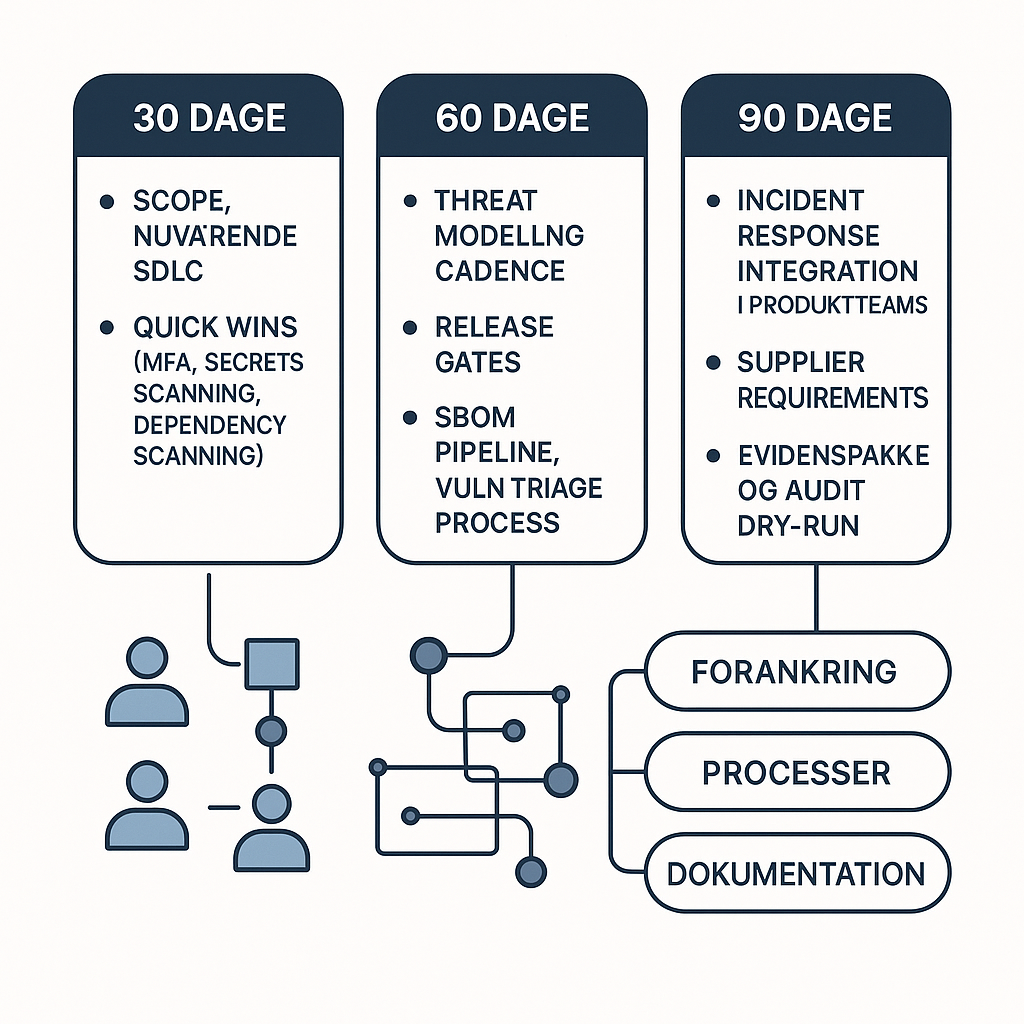
Hvis du leder efter en konkret og realistisk plan for at løfte software security uden at bremse udviklingstempoet, er du det rette sted. Denne artikel giver en 30/60/90-dages køreplan, der kan implementeres i en moderne agile/DevOps-organisation, med tydelige leverancer, ansvar og afhængigheder.
Du får en praktisk opskrift på, hvordan du går fra “vi ved godt, vi burde” til forankrede processer, målbar dokumentation og gentagelige arbejdsgange i jeres SDLC. Undervejs får du quick wins, release gates, en SBOM-pipeline, en sårbarhedstriage og en måde at integrere incident response i produktteams, så I kan stå stærkere over for krav, kunder og audits.
Hvad planen handler om: sikker SDLC som forankring, processer og dokumentation
En sikker SDLC (Secure Software Development Lifecycle) er en ramme for at bygge og vedligeholde software, hvor sikkerhed er integreret i hele livscyklussen: krav, design, udvikling, test, release og drift. Det betyder noget, fordi det reducerer risikoen for fejl, forkorter tiden fra fund til fix og gør det muligt at dokumentere, at I arbejder systematisk med sikkerhed, ikke kun ad hoc.
Nesp.ONEs vinkel kan opsummeres som forankring + processer + dokumentation i jeres eksisterende agile/DevOps-flow. Forankring sikrer ejerskab i teams og ledelse. Processer gør arbejdet gentageligt. Dokumentation skaber evidens, så I kan bevise over for kunder, revisorer og interne stakeholders, at kontrollerne faktisk bliver udført.
Mini-konklusion: Når sikkerhed gøres til et arbejdssystem i stedet for et projekt, bliver det billigere at drive og lettere at skalere.
Før du starter: scope, baseline og beslutninger der ikke kan udskydes
Den største fejl i mange sikkerhedsprogrammer er at starte med værktøjer før scope. Brug i stedet de første dage på at definere, hvad planen dækker: produkter, services, repos, build-systemer, cloud-konti, tredjepartsleverandører og release-frekvens.
Lav et “nu-billede” af jeres SDLC
Dokumentér kort, hvordan en ændring bevæger sig fra backlog til produktion: hvilke miljøer, tests, approvals og deploy-trin. Notér også, hvor data flyder, hvilke hemmeligheder der bruges, og hvor dependencies kommer fra. Det behøver ikke være perfekt, men det skal være sandt.
Fastlæg styringsprincipper
Beslut, hvem der kan stoppe en release, hvad der er “must fix”, og hvad der kan accepteres som risiko. Uden disse principper ender I i uendelige diskussioner, når første kritiske sårbarhed dukker op tæt på release.
- Scope: hvilke produkter og repos indgår i første bølge
- Risikokriterier: definition af kritisk/høj/medium og SLA for udbedring
- Release-autoritet: hvem kan gate, og hvornår
- Dokumentationsniveau: hvad skal gemmes som evidens
- Kommunikation: faste kanaler mellem platform, produkt og ledelse
Mini-konklusion: En ærlig baseline er ofte mere værd end en ambitiøs strategi, fordi den kan omsættes til handling i morgen.
Dag 0–30: quick wins der reducerer risiko med det samme
I de første 30 dage handler det om at sænke sandsynligheden for de mest almindelige hændelser: konto-overtagelse, lækkede secrets og kendte sårbarheder i dependencies. Det er også her, du skaber momentum ved at levere synlige forbedringer uden at omkalfatre hele pipeline.
MFA, adgangsmodel og kontohygiejne
Aktivér MFA på alle centrale systemer: Git-hosting, CI/CD, cloud-console, artifact registry og ticketing. Gå efter enhedsnær MFA eller passkeys, og fjern delte konti. Hvis I har break-glass konti, skal de være få, loggede og testede.
Secrets scanning og dependency scanning som standard
Indfør secrets scanning i repos og i CI, og gør det nemt at rotere nøgler. Kobl dependency scanning på buildet, så teams ser findings tidligt. Start med at sætte alerts og synlighed, før du gør det hårdt blokkerende, så du ikke skaber modstand.
- Slå secrets scanning til på alle repos og aktiver pre-commit hooks hvor muligt
- Indfør dependency scanning på build og pull requests
- Etabler en enkel proces for rotation af kompromitterede credentials
- Definér et minimumskrav: ingen hårdkodede secrets, og ingen kritiske kendte CVE’er ved release
- Få platform teamet til at levere standard templates, så udviklere ikke skal opfinde det selv
Hvad koster det? Typisk er MFA og basal scanning primært en tidsinvestering i opsætning og drift. Hvis I vælger kommercielle tools, skal I regne med licenser, men de første 30 dage kan ofte løses med platform-funktioner og eksisterende DevOps-værktøjer.
Mini-konklusion: Quick wins virker kun, hvis de lander som standarder i hverdagen, ikke som engangsoprydning.
RACI light: hvem gør hvad, og hvilke afhængigheder bider jer senere
Forankring kræver klare roller. Her er en “RACI light”, der passer til en softwarevirksomhed med platform team, produktteams og ledelse. Målet er at undgå, at sikkerhed bliver “nogens” sideprojekt.
- Ledelse: Accountable for risikoniveau, budget og prioritering; godkender release-politikker
- Platform team: Responsible for CI/CD-standarder, scanning, templates og central logging
- Udviklere i produktteams: Responsible for at fixe findings, skrive secure code og følge gates
- Security/Compliance-funktion: Consulted om policy, threat modeling, triage og evidens; driver læring
- QA/Release manager: Responsible for release checks, ændringsstyring og koordinering
Typiske afhængigheder: Platform teamet skal kunne ændre pipelines hurtigt. Produktteams skal have tid i sprinten til udbedringer. Ledelsen skal bakke op, når en release bliver stoppet. Hvis én af disse svigter, bliver resten symbolpolitik.
Mini-konklusion: Det er ikke nok at “eje sikkerhed” centralt; teams skal kunne udføre den i deres daglige flow.
Dag 31–60: threat modeling cadence, release gates og SBOM som pipeline-output
Når quick wins kører stabilt, er næste skridt at gøre sikkerhed til en gentagelig rytme. I denne fase flytter I fra scanning til styring: hvornår tænker vi i trusler, hvornår stopper vi releases, og hvordan dokumenterer vi, hvad der er i vores software.
Threat modeling cadence uden tunge workshops
Threat modeling fejler ofte, fordi det bliver en sjælden, stor øvelse. Gør det i stedet til en cadence: en kort session ved nye features, nye dataflows eller nye integrationsmønstre. Brug en enkel skabelon: aktiver, angrebsflader, misbrugsscenarier, kontroller og residual risiko. Hold det på 45–60 minutter, og sørg for at output bliver omsat til backlog-items.
Midt i denne fase giver det mening at bruge en ekstern eller intern reference for, hvordan krav kan omsættes til en praktisk plan; et eksempel på sådan en struktur findes i en CRA roadmap, som kan inspirere til at koble krav, evidens og engineering-arbejde sammen.
Release gates der matcher jeres modenhed
Release gates skal være skarpe nok til at ændre adfærd, men ikke så stramme at teams omgår dem. Start med to gates: ingen lækkede secrets, og ingen kendte kritiske sårbarheder i runtime dependencies. Udvid derefter med signeret build, branch protection og krav om code review på sikkerhedskritiske ændringer.
SBOM pipeline: gør det automatisk og versionsbundet
En SBOM (Software Bill of Materials) er en maskinlæsbar liste over komponenter og versioner i jeres build. Den er central for sårbarhedshåndtering, kundeforespørgsler og compliance. Generér SBOM i CI, gem den som artifact, og bind den til en release-version, så I altid kan svare på “hvad var i produktion den dag”.
Mini-konklusion: Når threat modeling, gates og SBOM bliver en del af jeres build-rytme, skifter sikkerhed fra debat til data.
Dag 31–60 fortsat: sårbarhedstriage som proces, ikke panik
De fleste organisationer drukner ikke i sårbarheder, men i manglende beslutningsregler. Derfor skal I etablere en triage-proces, der er hurtig, konsekvent og dokumenterbar.
Bedste praksis er at kombinere scanner-fund med kontekst: er komponenten i brug, er den interneteksponeret, har den kendt exploit, og hvilken kompensationskontrol findes. Brug en enkel scoring og knyt det til SLA’er. Lav en ugentlig triage-rytme, og en “fast lane” for kritiske issues.
- Indbakke: hvor findings lander, og hvem der overvåger den dagligt
- Triage: klassificér, dedupliker, og afgør om fundet er reelt
- Tildeling: send til rette team med deadline og acceptance-kriterier
- Udbedring: patch, opgrader, eller mitigér med konfiguration
- Undtagelser: tidsbegrænsede risk acceptances med ejer og begrundelse
- Evidens: gem beslutning, dato, og link til commit eller change
Typiske fejl: at behandle alle findings ens, at mangle ejerskab, eller at acceptere risiko uden udløbsdato. Undgå dette ved at kræve en navngiven risiko-ejer og en plan for opfølgning.
Mini-konklusion: En rolig triage-proces er en af de billigste måder at få mere sikkerhed pr. udviklertime.
Dag 61–90: incident response ind i produktteams og “security som driftsdisciplin”
I de sidste 30 dage handler det om at blive robust: ikke kun at forebygge, men at opdage, reagere og lære. Incident response må ikke være en central “brandstation”, som produktteams aldrig møder før krisen.
Integrér incident response i teamets arbejdsgange
Gør IR praktisk: definér severity-niveauer, kontaktveje og beslutningspunkter. Læg en letvægts runbook i teamets repo, og træn den med en tabletop-øvelse pr. kvartal. Sørg for at logs og alarmer er tilgængelige for dem, der skal handle, og at der er klare regler for, hvornår en hændelse eskaleres.
Læring og forbedring uden blame
Efter en hændelse skal output være forbedringer i proces og teknik: nye tests, bedre alerts, bedre hardening. Hold fokus på systemer, ikke personer, og lad læring blive til backlog-items med prioritet.
Mini-konklusion: Når teams kan reagere selv, falder MTTR, og sikkerhed bliver en del af leveringsevnen.
Dag 61–90 fortsat: leverandørkrav, evidenspakke og audit dry-run
Selv hvis jeres egen kode er stærk, kan leverandørkæden trække jer ned. Derfor skal I i denne fase få styr på supplier requirements og jeres evidenspakke, så compliance ikke bliver et scramble.
Start med en enkel leverandørstandard: krav til MFA, patching, logging, datahåndtering, underleverandører og rapportering af hændelser. Indfør en risikobaseret vurdering, så kritiske leverandører får mere kontrol end små tools. Hold det pragmatisk og knyt det til kontrakt- og onboarding-processen.
Evidenspakken bør samle det, en auditor eller kunde typisk beder om: SDLC-beskrivelse, release gates, triage-logs, SBOM-eksempler, threat modeling-output, IR-runbooks og træningsbeviser. Lav derefter en audit dry-run: én intern gennemgang, hvor I simulerer spørgsmål og tester, om I kan finde dokumentationen hurtigt.
- Definér minimumskrav til leverandører og få dem godkendt af ledelsen
- Opdatér onboarding, så kravene bliver fulgt konsekvent
- Byg en evidensmappe med links til kilder, ikke kopierede snapshots
- Kør en dry-run og noter huller: manglende logs, uklare ejere, ufuldstændige beslutninger
- Prioritér lukning af huller som engineering-arbejde, ikke kun dokumentarbejde
Hvad koster det? Her ligger omkostningen ofte i koordinering: juridisk, procurement, platform og produkt. Men når evidens skabes løbende i DevOps, falder audit-omkostningen markant over tid, fordi I ikke skal rekonstruere historik.
Mini-konklusion: En audit dry-run er ikke et compliance-stunt; det er en stresstest af jeres processer og jeres evne til at bevise dem.
De mest almindelige faldgruber og hvordan I undgår dem i praksis
Selv en god plan kan fejle, hvis den ikke passer til jeres kultur og leverancemodel. Her er de fejl, der oftest dukker op, og de konkrete modtræk.
- Faldgrube: scanning uden ejerskab. Løsning: tildel findings til teams med SLA og tydelige acceptance-kriterier
- Faldgrube: for hårde gates for tidligt. Løsning: start med synlighed, derefter gradvis enforcement
- Faldgrube: “security som kontrolinstans”. Løsning: bygges som enablement, templates og coaching
- Faldgrube: dokumentation som eftertanke. Løsning: generér evidens automatisk i pipeline og issue-tracking
- Faldgrube: undtagelser uden udløb. Løsning: tidsbegrænsede risk acceptances med navngiven ejer
- Faldgrube: threat modeling som engangsbegivenhed. Løsning: fast cadence koblet til ændringer i arkitektur og dataflow
Mini-konklusion: De fleste problemer er ikke tekniske; de handler om at gøre det let at gøre det rigtige og dyrt at ignorere det.
Sådan bruger du planen i morgen: en enkel opsummering til handling
Hvis du skal omsætte dette til første sprint, så start med tre ting: dokumentér jeres nuværende SDLC, slå MFA og scanning til, og aftal en triage-rytme. I næste sprint lægger du threat modeling cadence og de første release gates ind, og i sprinten efter bygger du SBOM som en del af release-outputtet. Inden dag 90 skal incident response være trænet i produktteams, leverandørkrav være på plads, og evidenspakken være testet i en dry-run.
Målet er ikke perfektion, men en sikkerhedsdisciplin der kan gentages, måles og bevises, mens I fortsat leverer software hurtigt. Når forankring, processer og dokumentation går hånd i hånd, får I en SDLC, der både styrker sikkerhed, reducerer stress og gør compliance til et biprodukt af god engineering.



